
 商标分类
商标分类  商标转让
商标转让 
一种基于编码-解码网络的音乐伴奏自动生成方法及其系统与流程
 2021-01-28 18:01:27|
2021-01-28 18:01:27| 297|
297| 起点商标网
起点商标网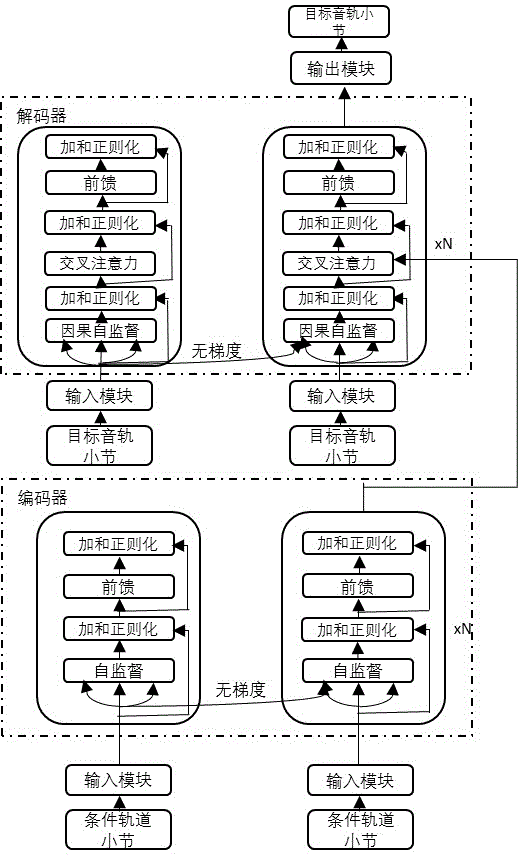
本发明涉及音乐设计领域,尤其涉及一种基于编码-解码网络的音乐伴奏自动生成方法及其系统。
背景技术:
:音乐是一种艺术形式和文化活动,其媒介是按时组织的声音。一般音乐的定义包括共同元件,例如音调(其支配旋律和和声),节奏(及其相关联的概念节奏,米,和关节),动态(响度和柔软性),和的声波品质音色和纹理(这是有时称为音乐声的“颜色”)。不同样式或类型音乐可能会强调、不强调或忽略其中的某些元素。音乐是用各种各样的乐器和声乐技术演奏的。在音乐技术的各种领域中,音乐的伴奏问题是一个很有挑战性的问题,自动伴奏技术旨在解决给定主音轨生成伴奏音轨的问题。随着人工智能和深度学习技术的快速发展,许多自动伴奏方法被提出。现有报道中提出了一种基于生成对抗网络的自动伴奏技术。这种方法将midi看做钢琴卷帘图,横轴为时间,纵轴为音高,用0和1表示当前位置和音高上有无音符触发,同时在生成音乐的过程中将图像领域广泛使用的生成对抗网络技术引入,通过设计多轨模型和时序模型,来解决音乐伴奏问题。多轨模型负责多轨道的相互依赖性,而时序模型处理时序依赖性。但是由于钢琴卷帘图的数据比较稀疏,训练很不稳定,实验结果也表明这种方法生成的音乐伴奏质量有限。同时,在自动作曲领域,前人也提出了很多基于序列模型的方法,但仅仅采用了一种解码器对一种音轨进行解码,只能实现针对单轨音乐进行续写,无法实现音乐的自动伴奏。综上所述,目前主流的自动伴奏和自动作曲技术无法满足生成高质量多轨自动伴奏的要求,这成为当前自动伴奏领域的巨大问题。技术实现要素:本发明的目的在于解决现有技术中的问题,为了克服现有技术中无法很好地生成高质量的自动伴奏的不足,本发明提供一种基于编码-解码网络的音乐伴奏自动生成方法及其系统。本发明所采用的一种基于编码-解码网络的音乐伴奏自动生成方法,包括如下步骤。1)获取源音乐训练集,每一个音乐作为一个训练样本,训练样本被标注为主音轨和伴奏音轨。2)建立编码-解码网络结构,包括编码神经网络和解码神经网络,所述的编码神经网络由多个编码器构成,解码神经网络由多个解码器构成。3)根据不同的音乐格式,读取源音乐并编码成不同的初始音乐表征,得到源音乐编码表征;随后从源音乐编码表征中获取主音轨语句(x1,…,xm)和源音乐编码表征语句的伴奏音轨(y1,…,yn),其中xi表示主音轨语句中的第i个符号,m表示主音轨语句中符号的数量,yi表示源音乐的伴奏音轨语句中第i个音符,n表示伴奏音轨中音符的数量,最后通过词嵌入将主音轨(x1,…,xm)和伴奏音轨(y1,…,yn)转成嵌入向量。4)将主音轨的嵌入向量输入到编码器神经网络进行n步编码,在编码过程中,将主音轨语句中位于前面的符号在编码器中计算得到的隐藏层序列存储至缓存中,并将缓存中的数据引入到后面符号的编码过程中,重复编码n次,得到编码器的输出作为主音轨编码后的音乐表征。将主音轨编码后的音乐表征以及伴奏音轨的嵌入向量作为解码神经网络的输入进行n步解码,在解码过程中,对解码器中的交叉注意模块进行掩码处理,并对伴奏音轨语句中位于前面的符号在解码器中计算得到的隐藏层序列存储至缓存中,并将缓存中的数据引入到后面符号的解码过程中,重复解码n次,将所有解码器的输出结果与伴奏音轨进行比对,对编码神经网络和解码神经网络进行训练,直至得到训练好的编码-解码网络模型。5)针对待处理的无伴奏音乐,获取音乐主音轨的嵌入向量,将嵌入向量作为训练好的编码-解码网络模型的输入,输出音乐伴奏;将得到的音乐伴奏与无伴奏音乐合成包含完整伴奏的音乐。本发明的另一目的在于提供了一种用于实现上述方法的音乐伴奏自动生成系统。包括:音乐样本采集模块:用于采集音乐数据作为源音乐训练集或者待处理无伴奏音乐,所述的源音乐训练集包括条件音轨和目标音轨,其中条件音乐标注为主音轨,目标音轨标注为伴奏音轨。编码-解码网络模块:配置有编码神经网络和解码神经网络,所述的编码神经网络由多个编码器构成,解码神经网络由多个解码器构成。音乐格式预处理模块:配置有不同的音乐预处理模式,通过识别不同的音乐格式选择相应的预处理模式。缓存模块:用于缓存每一个编码器和解码器的隐藏层输出信息。训练模块:用于在训练阶段更新编码-解码网络模块的参数。音乐合成模块:用于将得到的音乐伴奏与无伴奏音乐合成包含完整伴奏的音乐并输出。与现有技术相比,本发明具备以下有益效果。(1)本发明创造性地将编码-解码结构应用于音乐自动伴奏领域,与传统的基于钢琴卷帘图的方法相比,本方法采用了序列模型,可以更加有效地表征音乐数据,并且,基于钢琴卷帘图的方法的序列很不稳定,而本发明的训练稳定、泛化性更好。(2)现有技术中应用于相关领域的序列模型只采用了解码器,只能对一种音轨进行解码,只能实现针对单轨音乐进行续写;而本发明采用了编码-解码结构,使用编码器对主音轨进行编码,使得本发明可以更好地建模音乐的主音轨的上下文信息,保证了自动伴奏的性能。(3)本发明采用的编码器和解码器是基于传统的transformer模型实现的,但是transformer每次处理的是当前的定长片段,不适用于对音乐的音轨进行编码和解码;而本发明会将前一次处理的片段信息存储起来,与当前片段信息组合,再进行处理,通过这样的方式实现了音轨上下文信息的融合,使得模型可以处理更长的片段,适用于较长的音乐数据,并利用融合的上下文信息提高了处理精度。(4)本发明采用了小节级的注意力机制,在音乐中,一个小节内的音符往往是高度相关的,因此在训练过程中,本发明对交叉注意模块应用掩码,以确保解码器中的每个符号只能看到同一小节的条件上下文,这样可以避免关注到不重要的其他信息影响解码过程。附图说明图1是本发明采用的编码-解码网络示意图。具体实施方式下面结合附图和具体实施方式对本发明做进一步阐述和说明。如图1所示,本发明利用基于编码-解码网络的音乐伴奏自动生成方法包括如下步骤。1)对于输入的多轨(或者单轨)音乐,训练由多编码器组成的编码神经网络。2)对于输入的多轨(或者单轨)音乐,得到编码神经网络的输出;该输出结合最终要生成的目标伴奏训练解码神经网络。3)对于待处理的无伴奏的多轨(或者单轨)音乐,根据编码神经网络和解码神经网络生成音乐伴奏,将得到的音乐伴奏与无伴奏音乐合成包含完整伴奏的音乐。在本发明的一项具体实施中,介绍了编码-解码网络结构的建立过程以及音乐数据的预处理过程。编码神经网络及解码神经网络的训练过程。首先,获取源音乐训练集,每一个音乐作为一个训练样本,每一个音乐训练样本包括条件音轨和目标音轨,其中条件音轨是主音轨,是模型的输入,目标音轨是伴奏音轨,是模型的输出。其次,建立编码神经网络和解码神经网络,所述的编码神经网络由多个编码器构成,解码神经网络由多个解码器构成;优选为transformer的编码器和解码器结构。但由于transformer每次处理的是当前的定长片段,不适用于处理长篇幅的音乐数据,因此,在transformer的基础上,将前一次处理的片段信息存储起来,与当前片段信息组合,再进行处理,实现上下文信息更好的融合。然后,对源音乐训练集进行处理。根据不同的音乐格式,将源音乐读取并编码成不同的音乐表征(比如remi表征或者基于pianoroll的表征)。具体的,对于不同的音乐格式,比如mp3、wav等,通过不同的音乐读取技术将音乐转成音乐序列,再根据不同的音乐编码方式比如midi或者remi编码等将音乐序列转成编码序列。以midi-like编码为例,midi-like编码将音乐序列编码成set_velocity,note_on,time_shift,note_off等组成的编码序列,例如:set_velocity<100>,note_on<70>,time_shift<500>,note_on<74>,time_shift<500>,note_off<70>,note_off<67>……。随后从源音乐训练集中获取源音乐编码表征的主音轨语句(x1,…,xm)和源音乐编码表征语句的伴奏音轨(y1,…,yn),其中xi表示主音轨语句中的第i个符号,m表示主音轨语句中符号的数量,yi表示源音乐的伴奏音轨语句中第i个音符,n表示伴奏音轨中音符的数量,最后通过词嵌入将主音轨(x1,…,xm)和伴奏音轨(y1,…,yn)转成嵌入向量;在实际操作中,由于主音轨和伴奏音轨长度很长,本发明将主音轨和伴奏音轨平均分成多段,每次只编码和解码一段,多段生成的伴奏音轨最终会组合成整个伴奏音轨。在本发明的一项具体实施中,介绍了编码-解码网络结构的训练过程。将主音轨的嵌入向量输入到编码器神经网络进行n步编码,在编码过程中,将主音轨语句中位于前面的符号在编码器中计算得到的隐藏层序列存储至缓存中,并将缓存中的数据引入到后面符号的编码过程中,重复编码n次,得到编码器的输出作为主音轨编码后的音乐表征。将主音轨编码后的音乐表征以伴奏音轨的嵌入向量作为解码神经网络的输入进行n步解码,在解码过程中,对解码器中的交叉注意模块进行掩码处理,并对伴奏音轨语句中位于前面的符号在解码器中计算得到的隐藏层序列存储至缓存中,并将缓存中的数据引入到后面符号的解码过程中,重复解码n次,将所有解码器的输出结果与伴奏音轨进行比对,对编码神经网络和解码神经网络进行训练,直至得到训练好的编码-解码网络模型。将缓存中的数据引入到后面符号的编码过程或解码过程中,具体为:首先将不经过梯度计算的缓存中的数据与上一层隐藏层的输出进行连接,连接后的数据分别作为下一层自注意力层中k通道和v通道的输入,上一层隐藏层的输出作为下一层自注意力层中q通道的输入,得到下一层隐藏层的输出;依次类推,直至完成n层编码或n层解码。进一步的,编码器使用条件轨道(输入的单轨或者多轨音乐)里面的每一个符号在每一步进行编码,在训练期间,前面符号计算得到的隐藏层序列被存储到了缓存里面并且固定住,这部分缓存会被用作附加的上下文信息。编码器的输出会作为解码器的输入。编码器的公式其中,代表第i步编码的编码缓存。这部分缓存是在前面几步计算出来的。具体的计算过程是:在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入,该段前面隐藏层的输出和前面段隐藏层的输出。这两个输入会被拼接然后用来计算当前段的键和值,具体计算公式如下:τ代表第τ段音乐,n代表编码器第n层,h表示隐层的输出,sg(·)表示停止梯度计算,w是模型参数,[]是向量拼接操作。是编码器中的q、k、v向量,是第τ+1段音乐在第n-1层的输出,是第τ段在第n-1层的输出,是拼接后的结果,是第τ+1段音乐在n层的输出。本发明采用的编码器采用相对位置编码,即会根据词之间的相对距离而非像transformer中的绝对位置进行编码。相对位置编码的计算如下所示:其中,exi、exj分别是第i个符号和第j个符号的嵌入向量,ri-j是第i个符号和第j个符号的相对位置向量,wk,r、wk,e、wq是参数矩阵,为可学习的矩阵;u和v为参数向量,为可学习的向量;表示转置,是第i个符号和第j个符号的相对位置编码结果。解码器目的是根据之前的符号和来自于编码器的上下文语义去生成现在的符号。在训练过程中,对交叉注意模块应用掩码,以确保解码器中的每个符号只能看到同一小节的条件上下文。解码器的计算公式。代表解码器缓存,这部分缓存是前面几步的计算的结果。代表小节内部所有的编码器输出。具体的计算过程是:在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入,该段前面隐藏层的输出和前面段隐藏层的输出。这两个输入会被拼接然后用来计算当前段的键和值,具体计算公式如下:τ代表第τ段音乐,n代表解码器第n层,h表示隐层的输出,sg(·)表示停止梯度计算,w是模型参数,[]是向量拼接操作。是解码器中的q、k、v向量,是第τ+1段音乐在第n-1层的输出,是第τ段在第n-1层的输出,是拼接后的结果,是第τ+1段音乐在n层的输出。解码器同样采用相对位置编码的概念,即会根据词之间的相对距离而非像transformer中的绝对位置进行编码。相对位置编码的计算如下所示:其中,是符号i,j的嵌入向量,是相对位置向量,其他参数都是可学习的向量或者矩阵。在本发明的另一个具体实施中给出了一种基于编码-解码网络的音乐伴奏自动生成系统。具体包括:音乐样本采集模块:用于采集音乐数据作为源音乐训练集或者待处理无伴奏音乐,所述的源音乐训练集包括条件音轨和目标音轨,其中条件音乐标注为主音轨,目标音轨标注为伴奏音轨。编码-解码网络模块:配置有编码神经网络和解码神经网络,所述的编码神经网络由多个编码器构成,解码神经网络由多个解码器构成。音乐格式预处理模块:配置有不同的音乐预处理模式,通过识别不同的音乐格式选择相应的预处理模式。缓存模块:用于缓存每一个编码器和解码器的隐藏层输出信息。训练模块:用于在训练阶段更新编码-解码网络模块的参数。音乐合成模块:用于将得到的音乐伴奏与无伴奏音乐合成包含完整伴奏的音乐并输出。其中,所述的音乐格式预处理模块包括:初始表征生成模块:用于读取源音乐并编码成不同的初始音乐表征。词嵌入模块:用于将主音轨和伴奏音轨的语句转成嵌入向量。其中,所述的编码-解码网络模块中的编码神经网络由多个编码器构成,在编码过程中,将主音轨语句中位于前面的符号在编码器中计算得到的隐藏层序列存储至缓存模块中,并将缓存中的数据引入到后面符号的编码过程中,重复编码n次。其中,所述的编码-解码网络模块中的解码神经网络由多个解码器构成,在解码过程中,对解码器中的交叉注意模块进行掩码处理,并对伴奏音轨语句中位于前面的符号在解码器中计算得到的隐藏层序列存储至缓存模块中,并将缓存中的数据引入到后面符号的解码过程中,重复解码n次。上述中的多个模块是通过一些接口进行通信连接,可以是电性或其它的形式。模块的划分并不局限于本申请所提供的具体实施方式。下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。实施例为了进一步展示本发明的实施效果,本发明在lmd的数据集上面进行了实验验证,lmd数据集包含21916个音乐片段,372339个小节,总时长255.13小时。本发明采用的音乐编码是midi-like基于事件序列的音乐编码。为了验证本发明的有效性,实验设计了多种评价指标,客观评测包括和弦准确性(ca)和音高平均重叠区域(dp)、音量平均重叠区域(dv)、时长平均重叠区域(dd)。表1实验结果cadpdd本方法0.45±0.010.58±0.010.55±0.01musegan0.37±0.020.21±0.010.35±0.01表1展示了本发明评测的结果,其中musegan是基于钢琴卷帘图的方法,可以看到,本发明的结果要大大优于musegan的结果,说明本发明创造性地将编码-解码结构应用于音乐自动伴奏领域取得了突破性的成功,通过将编码器和解码器中前一次处理的片段信息存储起来,与当前片段信息组合,再进行处理,通过这样的方式实现了音轨上下文信息的融合,使得模型可以处理更长的片段,适用于较长的音乐数据,并利用融合的上下文信息提高了处理精度,同时利用序列模型能够可以更加有效地表征音乐数据,解决了钢琴卷帘图的方法的序列很不稳定的问题。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips